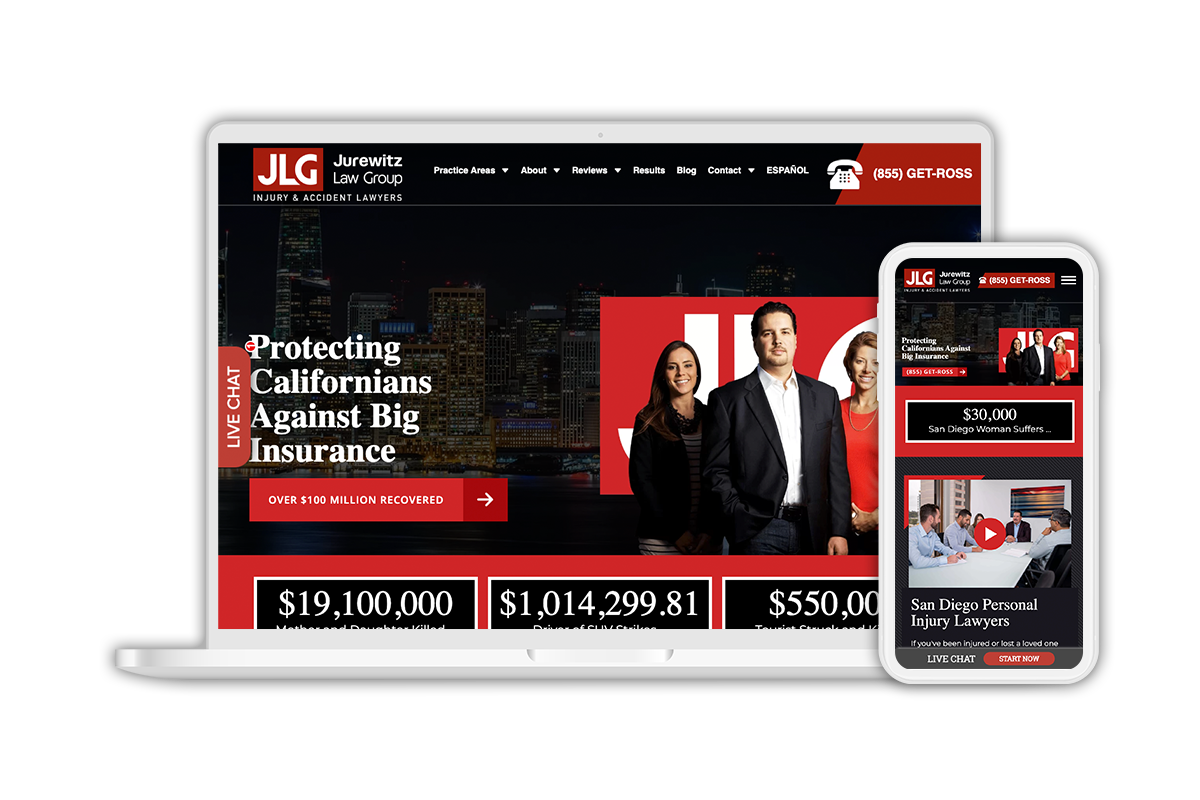
Attractive Websites
Own a website that converts.
Browse our premium, attractive websites built to help you convert more visitors into clients and ultimately grow your business. Our website designs have won awards such as the Web Awards Legal Standard of Excellence for our design, content, and interactivity.
Don’t see what you’re looking for? Our talented development team can make your dream site a reality. For quotes on special-order custom websites, call us, chat with us, or fill out a form and we will come up with a plan specifically for your law firm.